
티스토리 뷰
데이터분석 프로젝트 : 전기차 데이터를 활용한 분석 데이터 제공
시행 목적
전기차를 구입하려는 사용자가 필요로 하는 정보를 제공하기 위해 전기차 데이터를 수집 하고
이를 데이터 베이스로 구축한다 .
수집된 데이터를 시각화 하여 제공할 수 있게 하고, 데이터를 분석하여 향후 전기차의 전망에 대해 예측한다.
나의 역할
1. [크롤링] 데이터 크롤링 두가지 하기
2. [정제] 전체차종의 보조금 데이터에서 인기차종의 데이터를 추출하여 연도별 인기차종의 보조금 합계구하기
3. [시각화] 지역별 인기차량의 판매량 데이터를 이용한 등치지도 그래프 작성
4. [시각화] 지역별 충전소 설치현황 데이터를 이용하여 등치 지도 그래프를 작성
필요한 데이터
1. 타고 홈페이지에서 인기차종 (판매대수 데이터프레임: pop_car_df) 를 크롤링 하기
2. 타고 홈페이지에서 자동차 보조금 (자동차 보조금 데이터프레임 : price_car_df) 를 크롤링하기
이번 글에서는 [ 1. 데이터 크롤링 두가지 중 첫번째 ]를 설명합니다.
1. 인기차종 (pop_car_df.ipynb) : (판매대수 데이터프레임 : pop_car_df)
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import warnings
from urllib.request import urlopen
from bs4 import BeautifulSoup as soup
from collections import Counter
warnings.filterwarnings(action='ignore')
plt.rcParams['font.family']='Gulim'
본격적인 코드 시작 전에 import 를 위와 같이 실시하였습니다.
그리고 타고 홈페이지에서 인기차종 페이지를 살펴봅니다 !
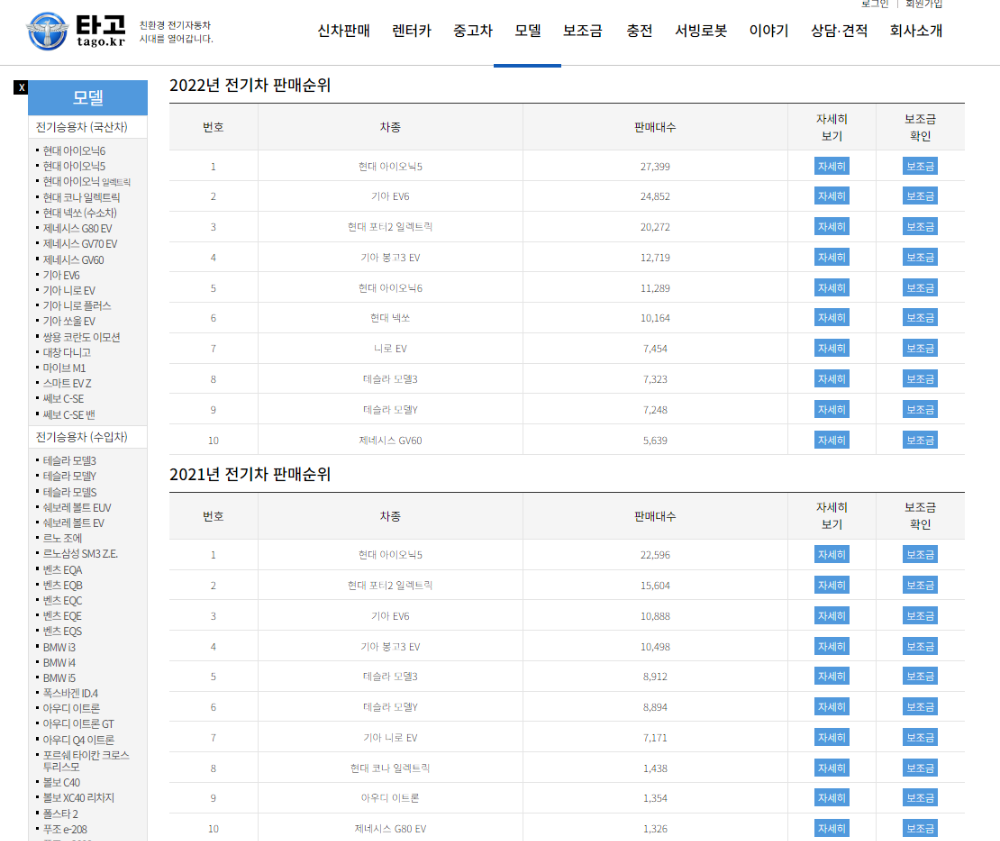
F12 를 눌러서 html을 확인하면 다음과 같습니다.


표가 table 로 들어가 있음을 확인 하였습니다.
판매 연도는 위에 테이블 위에 <h5> 태그의 class가 보입니다! 이걸 활용하였습니다.

target="https://tago.kr/model/order.htm" # 차량 인기순위 파악 주소
html = urlopen(target)
bs = soup(html.read(),'html.parser')
list_cars = bs.find_all('table')
list_cars에 table 태그의 html을 받아왔습니다.
실제로 list_cars를 확인해보면 아래와 같이 출력됩니다.

target="https://tago.kr/model/order.htm" # 차량 인기순위 파악 주소
html = urlopen(target)
bs = soup(html.read(),'html.parser')
list_cars = bs.find_all('table')
j=0
pop_car_df=pd.DataFrame()
for list_car in list_cars:
j=j+1
for i in list_car.find_all('tr')[1:]:
year = bs.find_all('h5',attrs={"class":"h5-tit"}) //h5태그에 저장된 판매년도 부분
year_num=(year[j-1].get_text()[0:4]) #year // 판매년도 부분에서 숫자 부분만 슬라이스
car_name=(i.find_all('td')[1].text) #차종
amount=(i.find_all('td')[2].text) #판매량
pop_car_df = pd.concat([pop_car_df,pd.DataFrame({"Car_name":[car_name],"판매량":[amount],"Year":[year_num]})])
pop_car_df=pop_car_df.reset_index()
pop_car_df = pop_car_df[['Year','Car_name','판매량']]# 데이터 프레임 열 순서 변경
테이블의 각 데이터는 <tr>을 기준으로 구분됩니다.
두번째 for문을 tr 태그를 기준으로 반복하였습니다.
<td>1</td>
<td>현대 아이오닉5</td>
<td>27,399</td>
<td>태그를 배열이라고 생각하면 0번주소에 인덱스, 1번주소에 차종, 2번주소에 판매량이 저장되어있습니다. 이걸 코드로 적용할때 다음과 같이 작성합니다.
car_name=(i.find_all('td')[1].text) #차종
amount=(i.find_all('td')[2].text) #판매량
연도는 테이블 안에 <caption> 이 아닌 위에 <h5> 태그에 있는 년도를 가지고 왔습니다.

year = bs.find_all('h5',attrs={"class":"h5-tit"}) //h5태그에 저장된 판매년도 부분
year_num=(year[j-1].get_text()[0:4]) #year // 판매년도 부분에서 숫자 부분만 슬라이스
year 에 h5태그 (클래스가 h5-tit인) 부분을 다 가지고 와서,
year_num 에서 판매년도 부분만 슬라이스 해서 배열처럼 만들어 줍니다.
년도에 2024년이 미리 추가 되어있는 부분이 있어서 제외하고 가져오도록 했습니다.
위의 코드로 저장된 pop_car_df 데이터프레임은 다음과 같습니다.

[링크]
Github Repository: https://github.com/notrowing/ElectricCar
GitHub - notrowing/ElectricCar
Contribute to notrowing/ElectricCar development by creating an account on GitHub.
github.com
타고 - 친환경 전기자동차 시대를 열어갑니다.
타고 - 친환경 전기자동차 시대를 열어갑니다.
tago.kr
'데이터 분석' 카테고리의 다른 글
| [python] 전기차 데이터를 활용한 분석 데이터 제공 1-2. 크롤링 (0) | 2023.11.18 |
|---|---|
| [python] 전자신문 뉴스 크롤링하기 3. 시각화 (0) | 2023.09.23 |
| [python] 전자신문 뉴스 크롤링하기 2. 통계분석 (0) | 2023.09.23 |
| [python] 전자신문 뉴스 크롤링하기 1. 수집, 가공 및 처리 (0) | 2023.09.23 |